

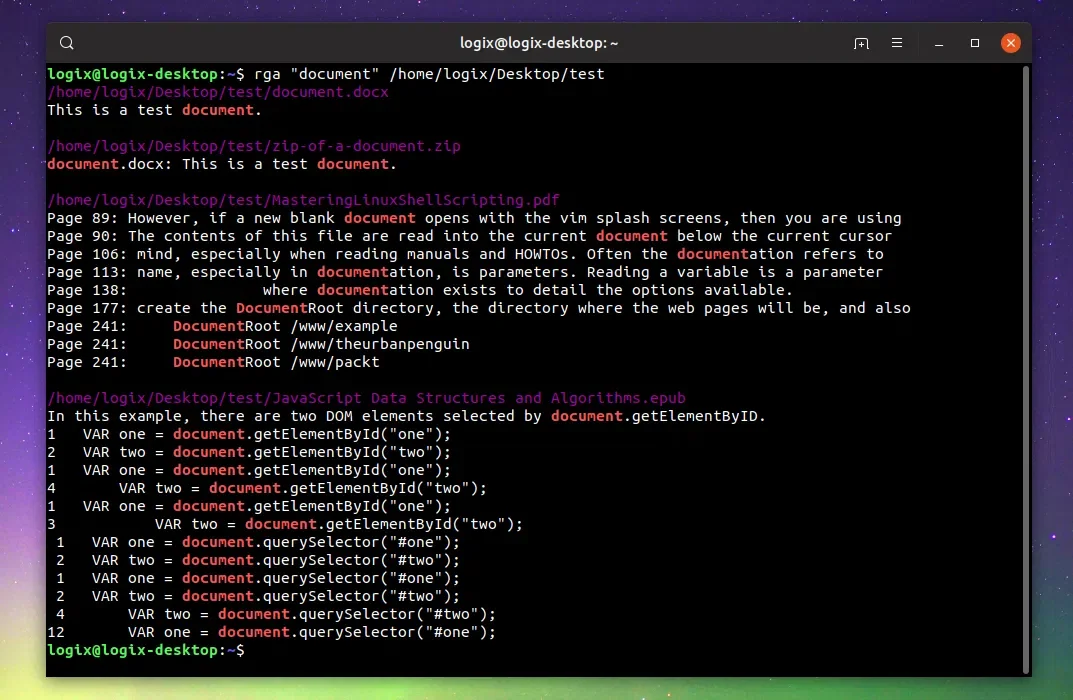
rga (ou ripgrep-all) é uma ferramenta de linha de comando para pesquisar recursivamente todos os arquivos em um diretório para um padrão regex, que roda em Linux, macOS e Windows. É um wrapper para ripgrep, o programa de pesquisa recursiva orientada por linha, além do qual permite a pesquisa em uma infinidade de tipos de arquivo como PDF, DOCX, ODT, EPUB, bancos de dados SQLite, legendas de filmes incorporados em MKV ou Arquivos MP4, arquivos como ZIP ou GZ e muito mais.
rga é ótimo quando você deseja pesquisar algum texto de um arquivo disponível em uma pasta com muitos documentos de vários tipos de arquivo, mesmo que alguns deles estejam disponíveis em arquivos.
E é rápido também, mesmo desde a primeira execução, graças ao multithreading. Em execuções subsequentes, porém, é ainda mais rápido (como se estivesse pesquisando em arquivos de texto simples) graças ao cache. O cache pode ser desabilitado se você desejar, no entanto, usando --rga-no-cache.
rga usa ripgrep (rg) para fazer a pesquisa, com algumas opções definidas. Para alguns tipos de arquivo, programas externos são usados para fazer o trabalho real, por exemplo, usando ffmpeg para ler legendas de arquivos mkv ou mp4, pandoc para converter documentos como EPUB, ODT, DOCX, FB2 ou IPYNB em texto simples como markdown, e grip e tar para ler o conteúdo do arquivo.
Além de poder pesquisar texto em documentos, arquivos e legendas embutidas em arquivos mkv ou mp4, o rga também pode pesquisar texto em imagens JPG ou PNG, ou arquivos PDF digitalizados, usando OCR (com o uso de tesseract). No entanto, esse recurso está desabilitado por padrão, porque é lento e não é útil na maioria das vezes, mas pode ser habilitado usando --rga-adapters=+pdfpages,tesseract.
Relacionado à pesquisa: Drill: Novo utilitário de pesquisa de arquivos na área de trabalho que usa rastreamento inteligente em vez de indexação
Esta é uma lista de adaptadores rga (ripgrep-all) e tipos de arquivo suportados:
ffmpeg:
pandoc:
poppler:
zip:
decompress:
Lê o arquivo compactado como um fluxo e executa um extrator diferente no conteúdo.
Extensões: . Tgz, .tbz, .tbz2, .gz, .bz2, .xz, .zst
Tipos Mime: application/gzip, application/x-bzip, application/x-xz, application/zstd
tar:
sqlite:
pdfpages (desativado por padrão):
tesseract (desativado por padrão):
Usa tesseract para executar OCR em imagens para torná-las pesquisáveis . Pode ser necessário -j1 para evitar sobrecarregar o sistema. Certifique-se de ter o tesseract instalado.
Extensões:. Jpg, .png
A página do projeto rga GitHub tem instruções para instalar a ferramenta no Linux, Windows ou macOS.
Lembre-se de instalar as dependências usadas pelos adaptadores rga para poder pesquisar em todos os tipos de arquivo que ele suporta (e o próprio ripgrep): ripgrep, pandoc, poppler (pacote poppler-utils no Debian/Ubuntu; o nome depende da distribuição Linux que você está usando), ffmpeg e cargo.
Você pode instalar o binário rga baixando o arquivo Linux x86_64 .tar.gz, extraí-lo e instalar os binários rga e rga-preproc em /usr/local/bin usando (execute o comando na pasta onde esses dois binários foram extraídos):
sudo install rga rga-preproc /usr/local/bin/
Após a instalação, use-o digitando rga seguido por sua consulta de pesquisa e a pasta onde procurar. Por exemplo:
rga "text to find" ~/Documents
Verifique também os sinalizadores rga disponíveis e suas informações de ajuda (rga --help).
Esse post foi traduzido do site LinuxUprising.com pela rtland.team.

Confira a versão original desse post em inglês:
rga: Search Text In PDF, Ebooks, Office Documents, Archives And More (ripgrep Wrapper)") vtm é um ambiente de desktop baseado em texto que é executado dentro de um terminal
vtm é um ambiente de desktop baseado em texto que é executado dentro de um terminal
") yewtube é uma ferramenta de Terminal para reproduzir o YouTube
yewtube é uma ferramenta de Terminal para reproduzir o YouTube
") Converta expressões em inglês simples em comandos usando o GPT-3 Powered Shell Genie
Converta expressões em inglês simples em comandos usando o GPT-3 Powered Shell Genie
") Como limpar o histórico do terminal (Bash Shell)
Como limpar o histórico do terminal (Bash Shell)
") Use o ChatGPT a partir da linha de comando com este wrapper
Use o ChatGPT a partir da linha de comando com este wrapper
") Guake Drop-Down Terminal Emulator tem nova versão
Guake Drop-Down Terminal Emulator tem nova versão
") NormCap: Ferramenta de captura de tela para texto usando OCR
NormCap: Ferramenta de captura de tela para texto usando OCR
") Upscayl AI Image Upscaler 2.5 adiciona opção para importar modelos personalizados, nova guia de configurações
Upscayl AI Image Upscaler 2.5 adiciona opção para importar modelos personalizados, nova guia de configurações
") GPU Screen Recorder para Linux adiciona suporte para GPUs AMD e Intel
GPU Screen Recorder para Linux adiciona suporte para GPUs AMD e Intel